Role DevOps
Overview
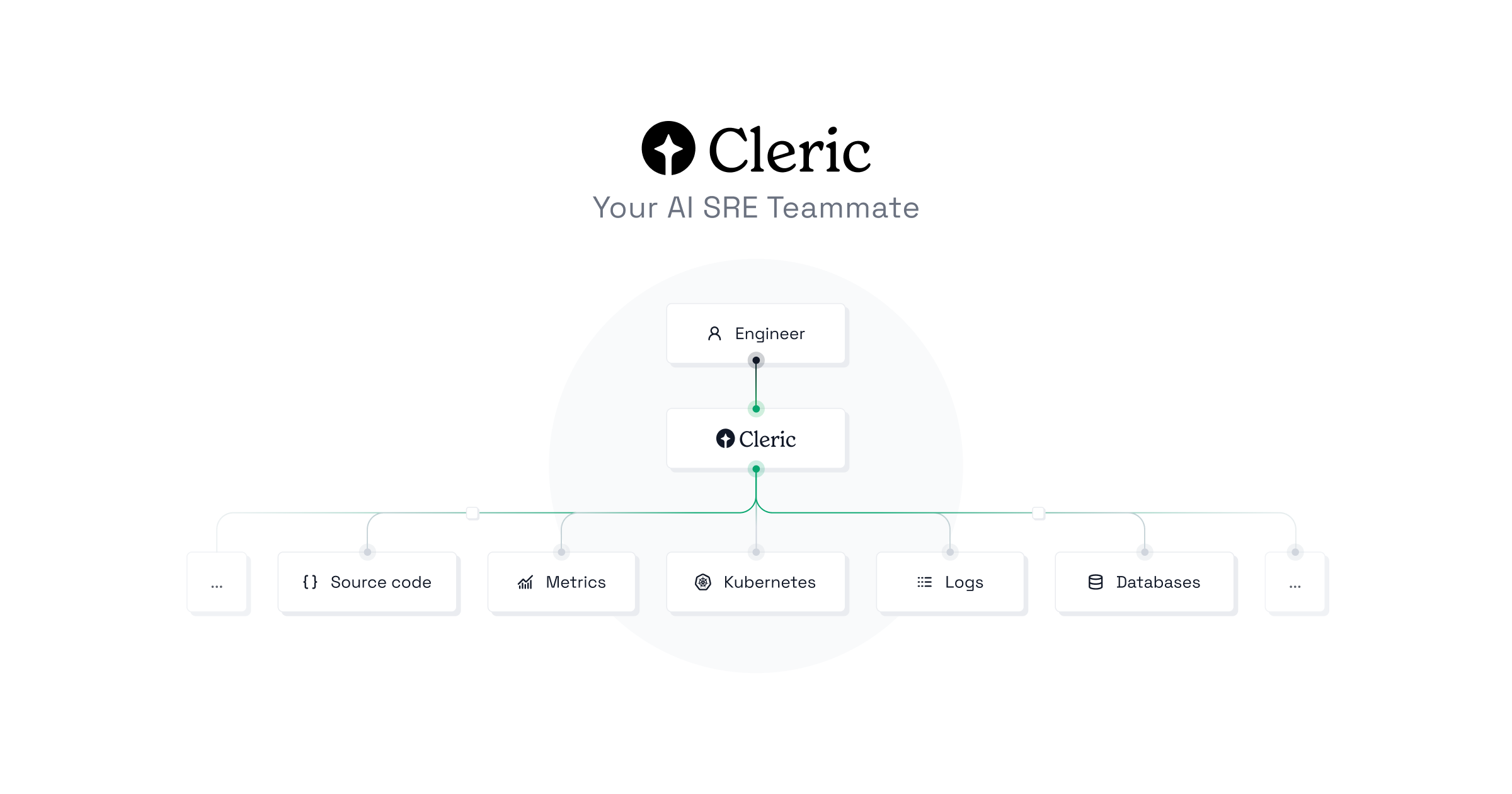
Cleric is the first autonomous AI site reliability engineer designed to assist on-call engineers by autonomously diagnosing and resolving alerts from production applications without the need for runbooks.
Key Features:
- Cleric autonomously identifies and resolves root causes of alerts from production applications, eliminating the need for manual intervention.
- It integrates seamlessly with a wide range of tools including GitHub, Google Cloud, AWS, Kubernetes, PagerDuty, Slack, Datadog, OpenSearch, Grafana, Confluence, Prometheus, and Jaeger, ensuring comprehensive coverage and compatibility.
- Cleric is designed to adapt and learn from each unique enterprise environment, enhancing its ability to manage and resolve production issues effectively over time.
Use Cases:
- On-call engineers can rely on Cleric to autonomously handle alert triage and root cause analysis, reducing their workload and response time.
- Organizations can integrate Cleric with their existing toolsets to create a more efficient and automated site reliability engineering process.
- Enterprises can leverage Cleric's learning capabilities to continuously improve their production environment management and reduce the frequency of recurring issues.
Benefits:
- Cleric frees on-call engineers from time-consuming investigations, allowing them to focus on more strategic tasks and reducing burnout.
- By automating the root cause analysis process, Cleric minimizes human error and increases the reliability and uptime of production environments.
- Cleric's ability to learn and adapt to specific enterprise environments ensures that it becomes more effective over time, providing long-term value and efficiency improvements.
Capabilities
- Manages and optimizes software infrastructure autonomously
- Diagnoses and resolves production issues in cloud-native environments
- Triages production application alerts and determines root causes
- Builds a comprehensive understanding of systems using documentation, metrics, logs, and alerts
- Connects to production environments using existing APIs and permissions
- Handles complex scenarios through reasoning from first principles
- Processes thousands of signals to detect and address potential issues
- Analyzes system metrics, logs, and traces to produce detailed findings
- Reduces operational noise by integrating with operational stacks
- Prioritizes critical system signals over less relevant alerts
- Generates and tests hypotheses about root causes simultaneously
- Queries system data from Datadog metrics, Kubernetes logs, and traces
- Documents investigations thoroughly, including commands, data, and decision pathways
- Identifies and resolves dependencies like Redis, ML inference, and resource constraints
- Compiles context from team discussions in Slack for improved insights
- Learns from engineering feedback to enhance decision-making capabilities
- Integrates seamlessly with tools like GitHub, Google Cloud, AWS, Kubernetes, PagerDuty, Slack, Datadog, OpenSearch, Grafana, Confluence, Prometheus, and Jaeger
- Adapts to enterprise-specific environments by learning continuously
- Resolves critical production issues autonomously based on learned patterns